Go Beyond Basics: Structuring Go Applications

Contributing to Video Intelligence & Computer Vision Solutions for Enhanced Business Operations
When starting to learn a new programming language, people first focus on understanding its syntax, relating it to what they already know. However, as they progress to structuring programs, their previous programming background can sometimes pose challenges rather than advantages.
The familiarity with syntax and concepts from a previous programming language can sometimes lead learners to approach structuring programs in the new language with preconceived notions or habits that may not be optimal or applicable all the time. This can hinder their ability to fully embrace the idiomatic patterns and best practices of the new language, potentially resulting in code that is less efficient, harder to maintain, or less scalable. So, let's see how we structure a Go project and why it's helpful.
The Usual Head-scratchers When You Start Coding
Usually when you complete coding a project, or a feature its moment of joy. But for me, it is always questions swirling in my head, and lots of decisions that I felt I had to make about my code, which had me thinking
Should I put everything in the main package?
How do I decide if something should be in its own package?
Should i start with one package and add more later?
Should I just use a framework?
What's the programming paradigm for Go?
How much should be shared between packages?
Whenever I found myself pondering these questions, I'd turn to the internet for answers. Unfortunately, most of what I found was subjective and heavily dependent on the specific project. It was disheartening to see that while there was plenty of discussion about design patterns, there was a noticeable lack of guidance on something as fundamental as structuring the application itself—like where exactly my files should go on my computer.
One thing about Go is its flexibility. While that's great in many ways, it also means there's no rigid template to follow. This can leave newcomers, like myself, feeling a bit lost about whether we're structuring our projects correctly or not.
Coming from a traditional object-oriented programming background, I found myself overcomplicating things more often than not. I was used to dealing with classes and objects in a certain way, and Go's approach, although simpler in many respects, felt unfamiliar and confusing at times.
So, if you've ever found yourself in a similar boat, wondering if you're doing it right, you're not alone. And don't worry—let's tackle these questions together and make sense of it all.
So what’s a good structure?
Consistency is key: Imagine one part of the project follows one principle, while another part follows something entirely different. If someone new were to dive into the codebase, they'd likely struggle to make sense of the project as a whole.
A solid code structure should be crystal clear, easy to navigate, and instantly understandable—requiring minimal digging through documentation to grasp what each part does and why it's there.
It should also be easy to update, meaning different parts should be loosely connected.
Remember, the design of your code should mirror how the software functions.
In Summary, Structuring code must make our life easy as a programmer. It should act as an ally, aiding us in our tasks rather than hindering us.
Lets dive in with an example
Consider an example project todo app, where
Users can add new tasks with details like title, description, and deadline.
Users can mark tasks as completed.
Users can list all tasks.
Users can filter tasks based on their completion status.
Option to store data either in any storage they want. For this example lets choose json or in memory(structs, maps etc)
Ability to include sample tasks/data.
Flat Structure
/
|-- data.go
|-- handlers.go
|-- main.go
|-- model.go
|-- storage.go
|-- storage_json.go
|-- storage_mem.go
| File | Description |
| data.go | Contains sample data, which could be retrieved from an external API or hardcoded. |
| handlers.go | Houses HTTP handlers for managing requests. |
| main.go | Serves as the entry point of the application. |
| model.go | Defines the data models, particularly for tasks in this example. |
| storage.go | Defines the core functionality for data storage. |
| storage_json.go | Provides an implementation for data storage using JSON files. |
| storage_mem.go | Provides an implementation for data storage using in-memory storage. |
The flat structure approach is straightforward and aligns well with Go's idiomatic patterns. Its simplicity helps avoid overcomplication and eliminates the possibility of circular dependencies since everything resides in the main package.
However, a downside of this approach is that it doesn't facilitate black-boxing or compartmentalisation. Since everything is within the main package, there's no inherent separation between components, potentially leading to accessibility issues between different parts of the codebase.
Another disadvantage is that by looking at the structure or filename, you cannot easily determine what the application does. Red Flag!
You have to dig through the code to understand to just tell what does the application do. Isn’t it bit tedious?
So let's see if we can break this up into a few smaller packages
Group by function
This was formerly known as “layered architecture”. your application can be divided into three distinct layers:
Presentation/User Interface:
- This layer handles the interaction between the application and the user. It encompasses components responsible for rendering user interfaces and managing user input.
Business Logic:
- The business logic layer contains the core functionality of the application. Here, the rules and operations that govern the behaviour of the application are implemented. This includes tasks such as data validation, processing, and decision-making etc.
External Dependencies/Infrastructure:
- This layer deals with interactions with external systems, packages, APIs, databases, or any other infrastructure components necessary for the operation of the application. It encapsulates the communication with external resources and manages data storage and retrieval.
This is similar to classic MVC which most of them would have heard in their developer journey.
With this our Application would be
/
|-- data.go
|-- handlers
| |-- tasks.go
|-- main.go
|-- models
| |-- tasks.go
| |-- storage.go
|-- storage
|-- json.go
|-- memory.go
This model discourages to use global state and encourage to put relevant things into the same package. With this, now we would have questions such as:
How do we use variables which are shared across layers, do we duplicate them?
Where should initialization occur?
Does main initialize everything? and then passes it into each model?
OR
Do we let each model to initialize its own storage or in the main?
One major challenge of this structure is the issue of circular dependencies. For instance, the storage package may rely on the model package to define tasks, while the model package may depend on the storage package to interact with the database.
Here's how the circular dependency manifests:
- In
storage.go(in themodelspackage), you might have methods that interact with the database or storage mechanism defined in thestoragepackage.
// storage.go in models package
package models
import "yourapp/storage"
type Task struct {
// Task fields
}
func SaveTask(task Task) error {
// Save task to storage
err := storage.Save(task)
return err
}
- In
json.goormemory.go(in thestoragepackage), you might have methods to perform storage operations.
// json.go or memory.go in storage package
package storage
import "yourapp/models"
func Save(task models.Task) error {
// Save task to JSON or memory storage
}
func RetrieveTask(taskID string) (models.Task, error) {
// Retrieve task from JSON or memory storage
}
As you can see, models depends on storage for storage operations, and storage depends on models to understand the structure of tasks. This creates a circular dependency issue.
To address these issues, let’s try to break it up into modules.
models package that specifies the storage operations it requires, and then implement this interface in the storage package. This way, each layer only depends on abstractions, not concrete implementations, reducing the likelihood of circular dependencies.Group By Module
In group by module lets divide them as tasks and storage. Here everything that deals with tasks goes to one package, and everything to do with storage goes to another package etc.
/
|-- tasks
| |-- tasks.go
| |-- handler.go
|-- main.go
|-- storage
|-- json.go
|-- memory.go
|-- data.go
|-- storage.go
Now things are grouped logically. It makes sense when you see it in terms of project itself. But its hard to as we would cause stutter when importing packages as tasks.tasks.go.
So lets try a different way, group by context.
Group by context
One of the key concepts in DDD is bounded context.
It is basically about the domain that you are dealing with and all the business logic in your app before you even write a single line of code.
Define your bounded context(s), the models within each context and the ubiquitous language.
A bounded context defines the explicit boundaries within which a particular model or concept applies. Within each bounded context, there is a shared understanding of the domain and a common language (known as ubiquitous language) that is used to describe concepts and interactions.
Suppose we are building a customer relationship management (CRM) system using Go. In our CRM system, we have two bounded contexts: Sales and Support.
Sales Bounded Context:
In the Sales context, our main concern is with managing leads, opportunities, and closing deals.
We define models such as Lead, Opportunity, and Deal within this bounded context.
The ubiquitous language in this context might include terms like "prospect," "qualified lead," "pipeline," and "conversion rate."
Support Bounded Context:
In the Support context, our focus shifts to managing customer issues, tickets, and providing assistance.
We define models such as Ticket, CustomerFeedback, and SupportAgent within this bounded context.
The ubiquitous language in this context might include terms like "ticket priority," "response time," "escalation," and "resolution."
Now, let's see how DDD helps us manage these contexts and their respective models in Go:
// Sales context
package sales
// Lead represents a potential customer.
type Lead struct {
ID int
Name string
Email string
Status string
// Other relevant fields...
}
// Opportunity represents a potential sale.
type Opportunity struct {
ID int
LeadID int
Amount float64
Probability int
// Other relevant fields...
}
// Deal represents a closed sale.
type Deal struct {
ID int
OpportunityID int
Amount float64
ClosedDate string
// Other relevant fields...
}
// Support context
package support
// Ticket represents a customer support ticket.
type Ticket struct {
ID int
CustomerID int
Subject string
Description string
Priority string
Status string
// Other relevant fields...
}
// CustomerFeedback represents feedback provided by a customer.
type CustomerFeedback struct {
ID int
CustomerID int
Feedback string
// Other relevant fields...
}
// SupportAgent represents a support team member.
type SupportAgent struct {
ID int
Name string
Email string
// Other relevant fields...
}
In this example, we have two separate packages (sales and support) representing different bounded contexts. Each package contains models that are specific to the context they belong to. By clearly defining these bounded contexts and their respective models, we can ensure that changes made within one context do not inadvertently affect the other. This helps in managing complexity and maintaining a clear understanding of the domain throughout the development process.
In group by context, we must categorize building blocks of the system, from our example:
Context: Task manager
Language: Task, Priority, Storage, ...
Entities: Task, User ...
Value_Objects: PriorityLevel, Deadline, ...
Aggregates: UserTasks, ...
Service: Task Creator, Task Lister, ...
Events: Task Created, Task Already Exists, Task Not Found, ...
Repository: Task Repository, User Repository
Language: This is something very important to define before we start coding as these terms are used not only by software developers, but also Product managers, support people, testers etc.
Example: It would cause a confusions when you call it storage, and someone else calls it repository, database etc. I would recommend to discuss it with every integral team of the company.Entity: When you think about entity, it would just be an abstract concepts which would then have instances.
Example: A "Task" can be considered an entity. Each task has attributes such as a title, description, due date, priority level, and status. Each task is unique and identifiable within the system.Value Object: They are similar to entity but they represent value of their own, i would say its properties to an entity.
Example: The "Priority Level" of a task can be a value object. It encapsulates properties such as importance, urgency, and impact, but it doesn't have its own identity. A high-priority task remains the same regardless of where it appears in the system.Aggregates: Aggregates are collections of related entities and value objects treated as a single unit. They combine entities together, by forming a relationship between each other.
Example: In our Instance, a meta entity called "UserTask" aggregate could be formed by combining a user entity with one or more task entities. This aggregate ensures that tasks are managed within the context of a specific user, allowing for transactional operations across related entities.Services: Its an Operation that should not be done by entity on its own. We must have services to do them as an instance. Services encapsulate behaviour or operations that don't naturally belong to any single entity but are relevant to the domain.
Example: In our example, it would be adding tasks, listing tasks etc. These operations involve multiple entities (e.g., tasks, users) and don't directly belong to any single entity.Events: It captures something interesting that happened in our application/system, that can affect the state of the application/system. They would be basically errors or acknowledgements.
Example: Events such as "TaskAdded", "TaskAssigned", "TaskCompleted", "TaskNotFound", etc., can be raised to notify other parts of the system about important actions or state changes.Repository: Provides a facade over some backing store so it sits between your domain logic and actual storage. They provide a simplified interface for accessing and manipulating domain objects without exposing the underlying storage details.
Example: TaskRepository" and "UserRepository" provide methods for querying, storing, updating, and deleting tasks and users, respectively.
In real world we can come across any software which can be built with DDD, and DDD can structure problems of any size and get us an abstract view on how we must be structuring our application.
So our project structure would somewhat look like this when we Group by Context
/
|-- adding
| |-- endpoint.go
| |-- service.go
|-- listing
| |-- endpoint.go
| |-- service.go
|-- tasks
| |-- task.go
| |-- sample_tasks.go
|-- users
| |-- user.go
| |-- sample_users.go
|-- main.go
|-- storage
|-- json.go
|-- memory.go
|-- type.go
Now our package name is based on what they provide but not what they contain, so we have adding, listing, tasks, storage as packages which make it easier to avoid circular dependencies. With this setup, modules such as "adding" and "listing" can interact seamlessly with "storage," which in turn accesses data from "tasks" and "users.” Now model packages such as tasks and users don’t care about storage package at all, as we have removed that link. Thus solving circular dependency in the application.
However, there's a challenge we face with this setup: how do we handle sample data? Up until now, we've been adding data directly within the main function, which limits our control over its execution. We lack the ability to manage sample data separately from the main application logic. Furthermore, with only one main function serving as the entry point to our application, adding additional entry points, such as a command-line interface (CLI) version that prompts users to add tasks under specific users, becomes cumbersome.
This poses a significant limitation to our current structure. We need a solution that allows us to manage sample data independently and facilitates the addition of alternative entry points to our application, such as a CLI version.
There is something that would help us with these problems: Hexagonal Architecture
Exploring Hexagonal Architecture
In the realm of software architecture, Hexagonal Architecture stands out as a powerful approach to designing applications. At its core, this architectural pattern emphasizes the clear separation of the core domain from external dependencies, which can range from databases and external APIs to cloud services and more.
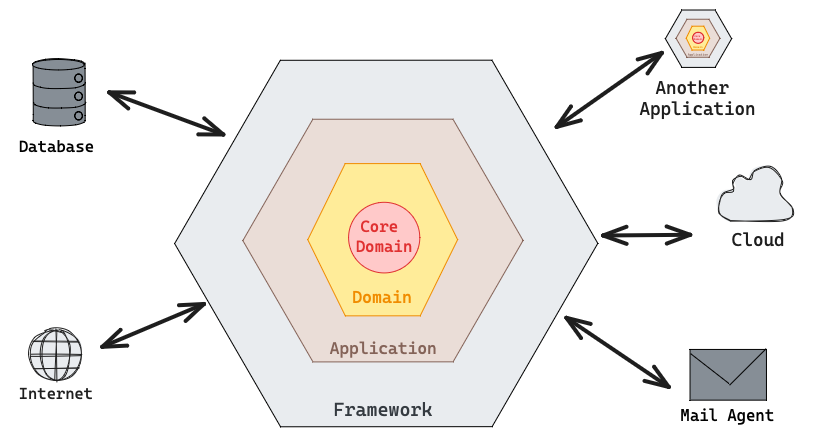
The guiding principle of Hexagonal Architecture is to facilitate changes within one part of the application without affecting unrelated parts. Unlike traditional models such as MVC, where input and output flow from top to bottom layers, in Hexagonal Architecture, inputs and outputs occur at the same level. This creates an external interface, akin to a hexagon, where interactions are uniform regardless of whether they are inputs or outputs.
Achieving Independence with Hexagonal Architecture
The key to achieving independence and flexibility lies in the way dependencies are managed. In Hexagonal Architecture, dependencies are strictly inward-pointing. This means that outer layers can freely interact with the domain, utilizing its entities and logic. However, the domain itself remains isolated and cannot reference anything external. This necessitates heavy usage of interfaces and inversion of control, allowing each layer to define interfaces that are implemented by their external counterparts.
So how do we achieve not having to change much or affect unrelated parts of the app. The key rule hex model is that dependencies are only allowed point inwards, so the outer layers can reach out to the domain as much as they like, they can use the definitions of entities defined in the model, but the domain absolutely cannot use reference anything outside of it. That implies heavy use of interfaces and inversion of control, we may need interfaces at every boundary between each layer. Domain logic would be mostly abstract and rest of the application implement those interfaces to satisfy the domain needs and those layers again define their interfaces which would be satisfied by their external layers.
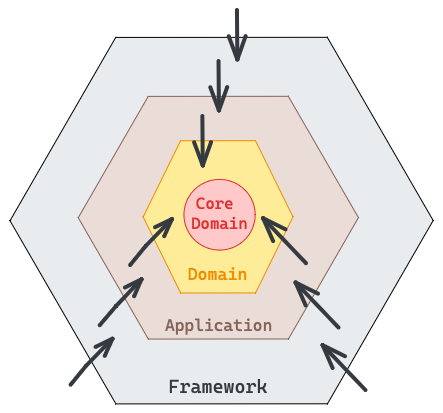
Structuring Projects with Hexagonal Architecture
Applying Hexagonal Architecture to project structure, we typically organize modules into directories such as "cmd" and "pkg." The "cmd" directory contains entry points to the application, while "pkg" houses the core logic and interfaces.
/
|-- cmd
| |-- task-server
| | |-- main.go
| |-- sample-data
| |-- main.go
|-- pkg
|-- adding
| |-- task.go
| |-- sample_tasks.go
| |-- service.go
|-- listing
| |-- task.go
| |-- user.go
| |-- service.go
|-- http
| |-- rest.go
| |-- handler.go
|-- storage
|-- json.go
| |-- task.go
| |-- data
| | |-- tasks
| | |-- users
| |-- repository.go
| |-- user.go
|-- memory
| |-- task.go
| |-- repository.go
| |-- user.go
It's common for developers to prefer additional subdirectories within the "pkg" folder for organizing domain-specific logic. That’s just a how you want to structure, i would say it would cause more nesting in the project structure.
Notice that each domain package, such as "listing" and "adding," contains its own version of struct definitions, like the "task" entity. This separation simplifies handling scenarios where certain properties may be required in one context but not in another. Example: “TaskID” might be essential for listing but probably not required in adding context.
Packages such as "HTTP" and "storage" are input and output interface where "HTTP" handles incoming requests via handlers, while "storage" provides the actual storage implementation.
The "cmd" and "pkg" directories serve as top-level directories in our project structure, reflecting a trend in the Go community and it has emerged over time to become a standard. Within the "cmd" directory, we place one or more binaries, such as "task-server" and "sample data," offering multiple entry points to the application. This setup enables adding sample data without the need to run the task server, enhancing flexibility.
The "pkg" directory houses all Go-related files, allowing for the organization of domain logic. Non-Go files, such as Dockerfiles or documentation, can be structured outside the "pkg" directory. Suppose you want to introduce a new client, such as a CLI service. In that case, you can simply create a new directory under "cmd" and generate a new binary, making the process straightforward and manageable.
This modular approach also facilitates the modularization of HTTP handlers within our application. We can anticipate future requirements, such as the integration of RPC or SOAP protocols, by simply adding subdirectories under the "HTTP" package. These new protocols can seamlessly utilize the same services defined under "listing" or "adding," ensuring consistency and reusability across different communication channels.
While this project structure offers numerous benefits, it's important to avoid overcomplicating simple applications. It's advisable to begin with a flat structure and gradually introduce modularization once you have a clear understanding of the domain boundaries and a functional Proof of Concept (PoC). You can also employee DDD in flat structure, remember that DDD does not enforce any structure. Just divide your application by context, it always tends to work in your favour.
You can use any frameworks which employees context grouping, but i would suggest to use any framework only if it fits your use case. Frameworks get your started without any need for you to write boiler plate code typing and they might give you some ideas and inspirations on the go. But keep in mind to just use the framework for your use case, but don’t inculcate the extra complexity that the framework inevitably brings with itself.
There is one interesting project that is worth mentioning - “go build template” by “thockin”, its like a suite in between because its a good shortcut as it predefines Dockerfiles and Makefiles for Go applications. While it sets up the "pkg" and "cmd" directories(but nothing inside it), it leaves the internal structure up to the developer, providing a convenient starting point while allowing flexibility in implementation. It just allows you cut a corner :)
Testing
Adhere to the principle of keeping _test.go files adjacent to the files they are testing rather than maintaining separate subdirectory for test files. This approach ensures that tests are closely coupled with the code they are validating, facilitating ease of navigation and maintenance.
Naming
Choose Descriptive Package Names:
Select package names that clearly indicate the functionality they provide.
Communicate what the package offers rather than listing its contents.
Example: Instead of naming a package "utils," consider "encryption" or "logging" to convey its purpose
Follow Go Conventions:
Adhere to established Go conventions outlined in resources like the "Effective Go" document. (https://talks.golang.org/2014/names.slide).
Maintain consistency and readability by following these conventions across the codebase.
Example: Use camelCase for variable and function names, and PascalCase for exported names.
Avoid Stutter:
Choose concise and clear names that avoid repeating information already implied by the context.
Eliminate redundancy to enhance clarity and maintainability.
Example: Prefer "strings.Reader" over "strings.StringReader" to avoid stutter and maintain clarity.
Keeping your main function as simple as possible is advisable.
In Summary
Project Structure:
Utilize two top-level directories:
cmdfor binaries andpkgfor packages.Organize packages by context rather than generic functionality for clarity and coherence.
Dependencies:
- Each package should manage its own dependencies, promoting encapsulation and modularity.
Other Project Files:
- Store additional project files (fixtures, resources, documentation, Dockerfiles, etc.) at the root directory for easy access.
Main Package:
- The main package orchestrates and initializes components, serving as the entry point of the application.
Global Scope:
- Minimize the use of global scope to reduce coupling and enhance encapsulation.
Credits
Peter Bourgon: peter.bourgon.org/blog/2017/06/09/theory-of-modern-go.html
Ben Johnson: medium.com/@benbjohnson/standard-package-layout-7cdbc8391fc1
Marcus Olsson: github.com/marcusolsson/goddd
